Demo 3: Indreprodukt-rum#
Demo af Magnus Troen. Revideret marts 2026 af shsp.
from sympy import*
from dtumathtools import*
init_printing()
Det sædvanlige indre produkt \(\left<\cdot, \cdot \right>\) i et indreprodukt-rum \(V\subseteq \mathbb{F}^n\) (altså, et vektorrum med reelle eller komplekse vektorer) er givet ved:
for alle \(\boldsymbol{x},\boldsymbol{y} \in V\). Se mere i lærebogen. Sympy har ikke en direkte indre-produkt-kommando, så vi skal selv kende til korrekte formel for hvert specifikt vektorrum.
Indre produkt i \(\Bbb R^n\)#
For \(\Bbb R^n\) forenkles det ovennævnte sædvanlige indre produkt til det velkendte prikprodukt. Altså kan vi, når vi har med reelle vektorer at gøre, benytte Sympys .dot-kommando:
x1 = Matrix([1,2,3])
x2 = Matrix([4,5,6])
x1.dot(x2), x2.dot(x1)

Et hurtigt manuelt tjek med \(\boldsymbol x_1 = (1,2,3)\) og \(\boldsymbol x_2 = (4,5,6)\) bekræfter resultatet:
Bemærk, at rækkefølgen i dette specifikke indre produkt ikke har nogen betydning.
Indre produkt i \(\Bbb C^n\)#
For \(\Bbb C^n\) bliver ovennævnte definition af det indre produkt ikke direkte til et prikprodukt men snarere en variant af et prikprodukt, hvor den højre vektor skal kompleks konjugeres. Det kan Sympy godt klare med .dot, hvis der tilføjes argumentet conjugate_convention = 'right':
x3 = Matrix([1, 2])
x4 = Matrix([2-I, 2])
x3.dot(x4, conjugate_convention = 'right')

Hvis dette føles lidt langt at skrive, er du velkommen til at lave dit eget lille script som dette:
def indre(x: Matrix, y: Matrix):
'''
Beregner det indre produkt af to vektorer med samme størrelse
'''
return x.dot(y, conjugate_convention = 'right')
MutableDenseMatrix.indre = indre
ImmutableDenseMatrix.indre = indre
I stedet for x3.dot(x4, conjugate_convention = 'right') kan du nu fremover blot taste x3.indre(x4) eller indre(x3,x4):
x3.indre(x4), indre(x3,x4), x4.indre(x3), indre(x4,x3)
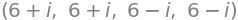
Bemærk, hvordan vektorernes rækkefølge har betydning denne gang, som forventet. Et hurtigt manuelt tjek med de to komplekse vektorer \(\boldsymbol x_3 = (1,2)\) og \(\boldsymbol x_4 = (2 - i,2)\) bekræfter resultatet:
Bemærk, at vores hjemmelavede Python-funktion indre også er brugbar på \(\Bbb R^n\), da den forenkles til prikproduktet ved reelle vektorer, hvor konjugering ikke har nogen betydning.
Norm#
Lærebogen definerer normen som \(\Vert \boldsymbol{x} \Vert = \sqrt{\left<\boldsymbol{x}, \boldsymbol{x} \right>}\), som med det sædvanlige indre produkt på vektorer blot bliver til Pytagoras’ sætning. Særligt for reelle vektorer opfattes normen selvfølgelig typisk som vektorlængden.
I stedet for manuelt at taste Pytagoras’ sætning ud, har Sympy en norm-kommando:
x1.norm(), x2.norm(), x3.norm(), x4.norm()

Bemærk, at denne version af normen også kaldes 2-normen (eller den Euklidiske norm eller \(\ell^2\)-normen), symboliseret ved \(||\cdot||_2\), hvis det skal tydeliggøres. Andre normer kan udregnes som følger - her \(||\boldsymbol x_1||_2\), \(||\boldsymbol x_1||_3\), \(||\boldsymbol x_1||_4\) og \(||\boldsymbol x_1||_\infty\) - men vi vil ikke dykke dybere ned i disse i dette kursus:
x1.norm(2), x1.norm(3), x1.norm(4), x1.norm(oo)
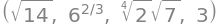
Foretrækkes den generelle norm-formel, så kan \(\Vert \boldsymbol{x} \Vert = \sqrt{\left<\boldsymbol{x}, \boldsymbol{x} \right>}\) nemt skrives manuelt i kode:
sqrt(x4.indre(x4)).simplify() , sqrt(x1.dot(x1)).simplify()
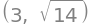
Vær blot varsom med at vælge den rette indre-produkt-formel (hvis normen ikke bliver et reelt tal, så ved du, at en forkert regnemetode er blevet valgt):
sqrt(x4.indre(x4)).simplify() , sqrt(x4.dot(x4)).simplify()
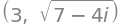
Projektioner på linjen#
Projektionsformlen#
Lærebogen forklarer, hvordan projektionen af en vektor \(\boldsymbol{x} \in \mathbb{F}^n\) på en linje \(Y = \operatorname{span}\{\boldsymbol{y}\}\) udspændt af en vektor \(\boldsymbol{y} \in \mathbb{F}^n\) kan bestemmes ved
hvor \(\boldsymbol{u} = \frac{\boldsymbol{y}}{||\boldsymbol{y}||}\).
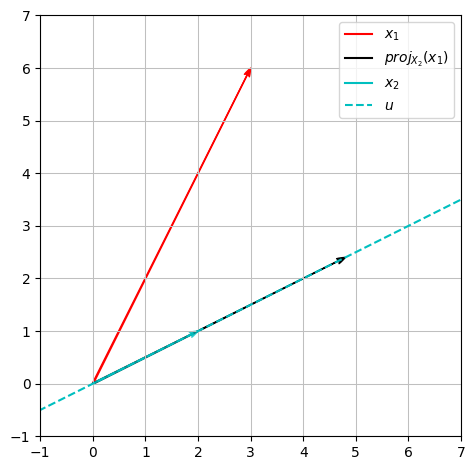
Som et eksempel lader vi \(\boldsymbol{x}_1, \boldsymbol{x}_2 \in \mathbb{R}^2\) være givet ved:
Lad os projicere \(\boldsymbol{x}_1\) ind på linjen givet ved \(U = \operatorname{span}\{\boldsymbol{x}_2\}\):
x1 = Matrix([3,6])
x2 = Matrix([2,1])
projU_x1 = x1.indre(x2)/x2.indre(x2) * x2 # Alternativt: indre(x1,x2)/x2.norm()**2 * x2
projU_x1
Da vi er i \(\mathbb{R}^2\), kan dette illustreres som følger:
x = symbols('x')
plot_x1 = dtuplot.quiver((0,0),x1,rendering_kw={'color':'r', 'label': '$x_1$'}, xlim = (-1,7), ylim = (-1,7), show = False, aspect='equal')
plot_x2 = dtuplot.quiver((0,0),x2,rendering_kw={'color':'c', 'label': '$x_2$', 'alpha': 0.7}, show = False)
plot_projX2 = dtuplot.quiver((0,0),projU_x1,rendering_kw={'color':'k', 'label': '$proj_{X_2}(x_1)$'},show = False)
plot_X2 = dtuplot.plot(x2[1]/x2[0] * x, label = '$u$',rendering_kw={'color':'c', 'linestyle': '--'}, legend = True,show = False)
(plot_x1 + plot_X2 + plot_projX2 + plot_x2).show()
Projektionsmatricen#
Lad os som et eksempel definere nogle vektorer i \(\Bbb C^4\):
c1 = Matrix([2+I, 3, 5-I, 6])
c2 = Matrix([1, I, 3-I, 2])
c1,c2
Lærebogen forklarer, hvordan projektionen \(\operatorname{Proj}_{\boldsymbol c_2}\), som projicerer inputvektorer ind på linjen udspændt af \(\boldsymbol c_2\), kan beskrives som en lineær afbildning:
hvor \(\boldsymbol{u} = \boldsymbol c_2/||\boldsymbol c_2||\). Afbildningsmatricen \(P=\boldsymbol{u}\boldsymbol{u}^*\) kaldes typisk for en projektionsmatrix. Bemærk, at asterisken \(^*\) angiver den adjungerede, altså konjugerede og transponerede, vektor/matrix, \(\boldsymbol u^*=\boldsymbol{\bar u}^T\).
u = simplify(c2/c2.norm())
P = expand(u*u.adjoint())
u,P
Med denne matrix er det nemt at udføre projektioner af vektorer in på linjen udspændt af \(\boldsymbol c_2\), fx en projektion af \(\boldsymbol c_1\), så \(\operatorname{Proj}_{\boldsymbol c_2}(\boldsymbol c_1)\):
simplify(P*c1)
En sammenligning med vores tidligere metode bekræfter resultatet:
simplify(c1.indre(u)/u.indre(u)*u)
Projektionen af \(\boldsymbol c_2\) ind på linjen, der udspændes af \(\boldsymbol c_2\), så \(\operatorname{Proj}_{\boldsymbol c_2}(\boldsymbol c_2)\), burde selvfølgelig ikke ændre på vektoren \(\boldsymbol c_2\) - lad os tjekke efter:
P*c2, c2
Ved første øjekast ser dette ikke just lovende ud, men glem ikke at simplificere:
simplify(P*c2), c2
Som forventet. Projektionsmatricen \(P\) er per definition hermitisk, hvilket vil sige, at \(P = P^*\). Dette kan verificeres manuelt:
simplify(P-P.adjoint())
eller med en dertilegnet kommando:
P.is_hermitian
True
Ortonormale baser#
Lærebogen definerer en mængde af vektorer som ortonormal, når alle vektorer i mængde har en norm på \(1\) og de alle er indbyrdes ortogonale, altså med indre produkter på \(0\).
Ortonormale baser viser sig enormt praktiske. Et eksempel er basisskifte, som bliver meget nemmere, når der benyttes ortonormale baser. Hvis vi for eksempel får givet en ortonormal basis \(\beta=(\boldsymbol{u}_1,\boldsymbol{u}_2,\cdots,\boldsymbol{u}_n)\) for et vektorrum \(V\), så findes koordinatvektoren \(\phantom{ }_\beta\boldsymbol{x}\) med hensyn til basis \(\beta\) for en vektor \(\boldsymbol x\in V\) jf. lærebogen ved:
(Sammenhold dette med dit arbejde i Matematik 1a, hvor vi løste lineære ligningssystemer for at finde sådanne koordinatvektorer.)
Manuelt tjek for ortonormalitet#
Som et eksempel er vi givet følgende liste af tre vektorer i \(\Bbb R^3\):
hvor \(\boldsymbol q_3\) er givet som krydsproduktet af de to andre.
q1 = Matrix([sqrt(3)/3, sqrt(3)/3, sqrt(3)/3])
q2 = Matrix([sqrt(2)/2, 0, -sqrt(2)/2])
q3 = q1.cross(q2)
q1,q2,q3
Det påstås nu, at disse udgør en ortonormal basis for \(\mathbb{R}^3\). Lad os eftervise den påstand ved manuelt at tjekke hver indre-produkt-kombination:
q1.indre(q1), q1.indre(q2), q1.indre(q3), q2.indre(q2), q2.indre(q3), q3.indre(q3)
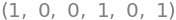
Kravene er opfyldt, så vi har hermed bekræftet, at \(\beta\) består af ortonormale vektorer. Ortonormale vektorer er lineært uafhængige, og tre lineært uafhængige vektorer i \(\Bbb R^3\) udspænder hele \(\Bbb R^3\). Vi konkluderer dermed, at \(\beta\) udgør en ortonormal basis for \(\mathbb{R}^3\).
Vi kan nu opskrive koordinatvektoren for en vektor som \(\boldsymbol{x} = (1,2,3)\) med hensyn til denne \(\beta\)-basis:
x = Matrix([1,2,3])
beta_x = Matrix([x.indre(q1) , x.indre(q2) , x.indre(q3)])
beta_x
Ortonormalitetstjek ved brug af rang#
Som et andet eksempel vil vi betragte listen af vektorer \(\gamma = (\boldsymbol v_1,\boldsymbol v_2,\boldsymbol v_3,\boldsymbol v_4)\), alle fra \(\mathbb{C}^4\), hvor
v1 = Matrix([2*I,0,0, 0])
v2 = Matrix([I, 1, 1, 0])
v3 = Matrix([0, I, 1, 1])
v4 = Matrix([0, 0, 0, I])
Vi søger en ortonormal basis for vektorrummet udspændt af \(\gamma\). Som det første kan vi tjekke, om vektorerne i \(\gamma\) udspænder hele \(\Bbb C^4\) eller kun et underrum deri:
V = Matrix.hstack(v1,v2,v3,v4)
V.rref(pivots=False)
Med en rang på fire har vi hermed bekræftet, at vektorerne i \(\gamma\) er lineært uafhængige, og da der er fire af dem, konkluderer vi, \(\gamma\) udspænder og udgør en basis for \(\Bbb C^4\). Dog ikke nødvendigvis en ortonormal basis. Et tjek for ortogonalitet og enhedslængde vil her vise, at en justering er nødvendig. Det kan Gram-Schmidt-proceduren ordne for os!
Gram-Schmidt-proceduren#
Vi vil nu udføre Gram-Schmidt-proceduren på eksemplet med fire vektorer \(\boldsymbol v_1,\boldsymbol v_2,\boldsymbol v_3,\boldsymbol v_4\) i \(\Bbb C^4\) fra forrige afsnit. Altså, vi vil nu “justere” de fire vektorer, således at vi opnår fire nye ortonormale vektorer, der udspænder samme vektorrum \(\Bbb C^4\).
Jf. lærebogen lader Gram-Schmidt-proceduren os opnå den første nye vektor \(\boldsymbol{u}_1\) ved en normalisering af \(\boldsymbol{v}_1\):
u1 = v1/v1.norm()
u1
efterfulgt af følgende udregning på hver af de andre vektorer \(\boldsymbol v_k\), én ad gangen:
som hver afsluttes med en normalisering:
w2 = simplify(v2 - v2.indre(u1)*u1)
u2 = expand(w2/w2.norm())
w3 = simplify(v3 - v3.indre(u1)*u1 - v3.indre(u2)*u2)
u3 = expand(w3/w3.norm())
w4 = simplify(v4 - v4.indre(u1)*u1 - v4.indre(u2)*u2 - v4.indre(u3)*u3)
u4 = expand(w4/w4.norm())
u1,u2,u3,u4
Vi bør eftertjekke, at \(\boldsymbol{u}_1,\boldsymbol{u}_2,\boldsymbol{u}_3,\boldsymbol{u}_4\) rent faktisk er ortonormale - herunder udfører ét enkelt sådant tjek; resten lader vi være op til læseren:
simplify(u1.indre(u2)) # Og så videre

Gram-Schmidt-proceduren kan blive langsommelig og udmattende for mængder med mange vektorer, men heldigvis har Sympy kommandoen GramSchmidt, der lader os finde resultet hurtigere:
y1,y2,y3,y4 = GramSchmidt([v1,v2,v3,v4], orthonormal=True)
y1,y2,expand(y3),expand(y4)
Unitære og (reelt) ortogonale matricer#
Jf. lærebogen kaldes en kvadratisk matrix \(U\) unitær, hvis den opfylder
For en reel matrix \(Q\in \mathsf M_n(\mathbb{R})\) forenkles adjungering \(Q^*=\bar Q^T\) til blot transponering \(Q^T\), og reelle kvadratiske matricer kaldes (reelt) ortogonale, hvis de opfylder
Bemærk, at (reelt) ortogonale matricer også er unitære.
Lærebogen fortæller videre, at en matrix er unitær, hhv. (reelt) ortogonal, hvis og kun hvis dens søjler er ortonormale. En matrix \(U = \left[\boldsymbol{u}_1, \boldsymbol{u}_2, \boldsymbol{u}_3, \boldsymbol{u}_4\right]\) dannet af de vektorer, vi opnåede med Gram-Schmidt-proceduren tidligere, vil derfor være unitær:
U = Matrix.hstack(u1,u2,u3,u4)
U
Den adjungerede matrix \(U^*\) af \(U\) er:
U.adjoint(), conjugate(U.T)
Vi bekræfter, at \(U\) ganske rigtigt er unitær:
simplify(U*U.adjoint()), simplify(U.adjoint()*U)
En matrix \(Q = \left[\boldsymbol{q}_1, \boldsymbol{q}_2, \boldsymbol{q}_3\right]\) dannet af de reelle \(\boldsymbol q\)-vektorer, som vi tidligere bekræftede som værende ortonormale, er (reelt) ortogonal:
Q = Matrix.hstack(q1,q2,q3)
Q
Vi bekræfter, at \(Q\) ganske rigtigt er (reelt) ortogonal:
simplify(Q*Q.T), simplify(Q.T*Q)